The 30-second version
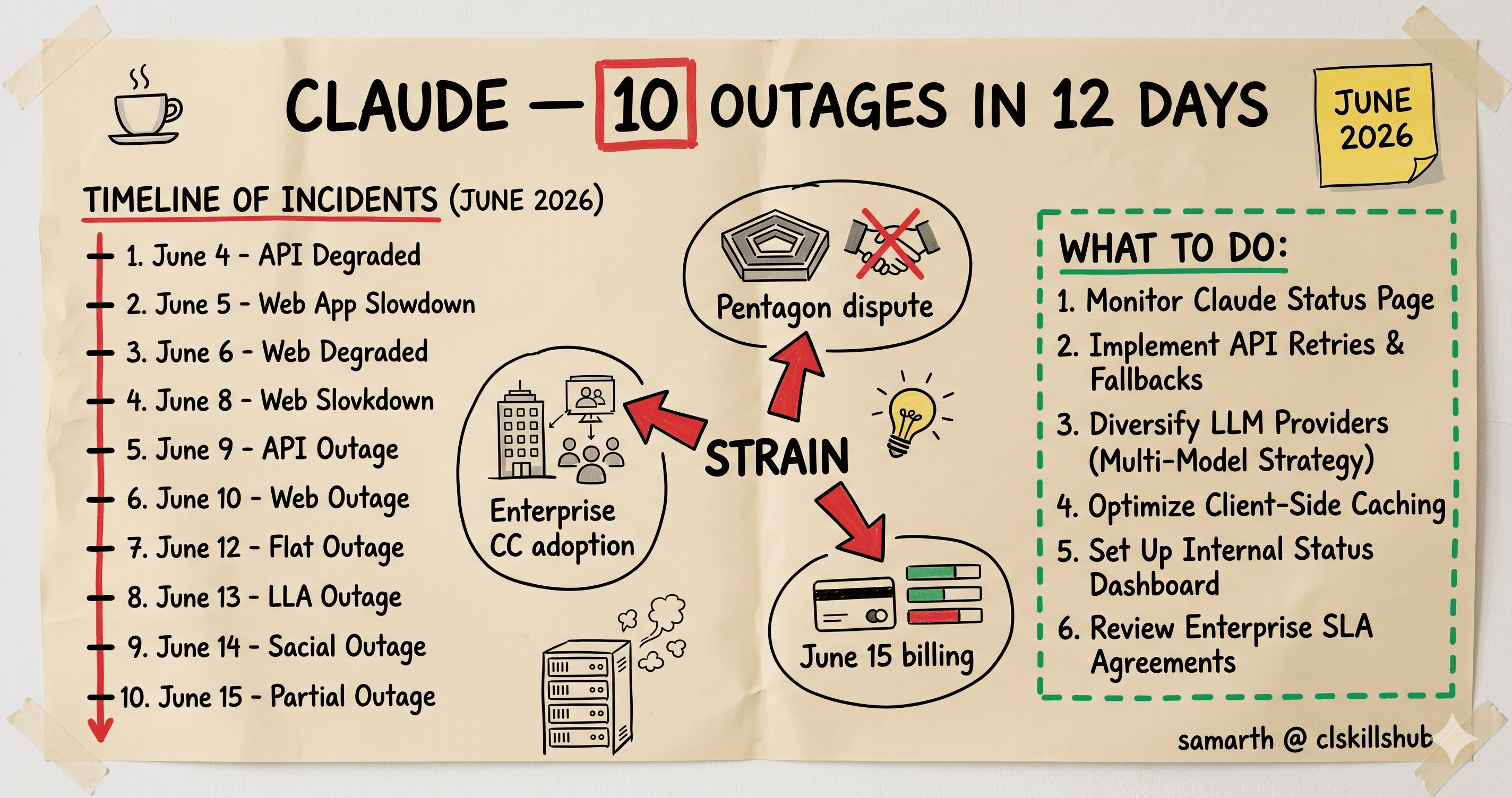
Between June 5 and June 16, 2026, Anthropic acknowledged ten significant Claude service disruptions on its public status page. The June 16 incident, the most recent, hit Opus 4.8 and Haiku 4.5 across all surfaces (claude.ai, the API, Claude Code, Cowork) and persisted past the first fix attempt at 14:00 ET. Anthropic publicly attributed the strain to two factors: enterprise Claude Code adoption growing faster than infrastructure can scale, and a download surge after the company's ongoing dispute with the US Department of Defense.
On June 17, the day after the outage, Anthropic shipped a substantive Claude Code release: auto mode landed on Bedrock, Vertex, and Foundry; file-write protection covers shell startup and build configs; a new /plugin list command shipped; and a long list of stream-handling, scrolling, and remote-session fixes landed.
This post covers the full timeline, the underlying causes Anthropic has publicly confirmed, the June 17 release, and the concrete steps every builder should take this week to insulate against ongoing disruption.
The 12-day timeline
From Anthropic's official status page (status.claude.com/history), the incidents from June 5 to June 16:
- June 5 — Brief elevated error rate on claude.ai
- June 6 — Two distinct incidents, both on the API
- June 8 — Claude Code intermittent connection drops
- June 9 — Sonnet 4.6 elevated latency
- June 11 — Opus 4.7 errors on the API, ~90 minutes
- June 12 — Multi-region failure affecting claude.ai
- June 14 — Opus 4.8 cold-start errors after deploy
- June 15 — Brief outage coinciding with the new billing structure rollout
- June 16 — The current incident. Opus 4.8 and Haiku 4.5 errors across all surfaces, investigation began at 17:29 UTC, first fix at 18:00 UTC, errors persisting at 18:15 UTC, full resolution later that evening.
The pattern is not random. The incidents cluster around model deploys (Opus 4.8 was newly promoted to default the prior week), peak-hour traffic in US business hours, and around feature releases (the June 15 billing change being the clearest example).
For builders, the practical lesson is that the disruptions are predictable in shape if not in time. They tend to hit during peak US business hours (which is most of the day for global users), during the rollout window of any new model or billing change, and they tend to last 30 minutes to several hours.
Why this is happening (Anthropic's own framing)
Anthropic has been unusually direct on the status page and in adjacent communications. The cited causes:
Demand growth from enterprise Claude Code adoption. Claude Code went general availability earlier this year and has been picking up steam, particularly in the enterprise AWS Bedrock and Google Cloud Vertex AI deployments. Anthropic confirmed in mid-June that Claude Code usage at the API level is now a meaningful percentage of all Claude usage. Each Claude Code session is API-heavy in a way that consumer chat sessions are not.
Download surge from the Pentagon dispute. Anthropic's ongoing legal dispute with the US Department of Defense (the company sued Defense Secretary Pete Hegseth in March after the DOD designated it a supply chain risk) has driven a paradoxical effect: the company has lost the Pentagon contract but gained substantial public visibility, including a measurable surge in new developer signups during May and June 2026. The strain on infrastructure is partly a story about Anthropic becoming more popular as a brand even as it loses one of its largest customers.
The new dual-billing structure rolling out June 15. Anthropic split programmatic Claude usage from interactive subscription limits starting June 15, with programmatic getting its own monthly credit pool billed at standard API rates. This rollout itself caused friction. The June 15 outage is widely understood to be related to the underlying infrastructure changes that the billing split required.
These are growing pains. They are not unprecedented for an AI company at Anthropic's scale (Stripe, AWS, and OpenAI all went through similar phases). But they are real, and they affect anyone building on Claude.
What also shipped: the June 17 Claude Code release
Anthropic deserves credit for shipping a substantive Claude Code release on June 17, the day after the worst recent outage. The team did not pause feature work to firefight reliability; the two efforts ran in parallel, which is the right call for a fast-moving product.
The biggest changes in the June 17 release:
Auto mode on Bedrock, Vertex, and Foundry
Auto mode is now available on AWS Bedrock, Google Cloud Vertex AI, and Microsoft Foundry for Opus 4.7 and Opus 4.8. Auto mode replaces permission prompts with background safety checks on third-party providers. To enable it: set the environment variable CLAUDE_CODE_ENABLE_AUTO_MODE=1.
For enterprise teams that run Claude Code through Bedrock for compliance reasons (HIPAA, FedRAMP, IL5), this is genuinely useful. Auto mode previously only ran through Anthropic's first-party API. Multi-cloud enterprises can now run the same Claude Code workflows with the same auto-mode behavior across their primary cloud provider.
This is also a partial answer to the reliability problem. If first-party Anthropic API is down, Claude Code running through Bedrock or Vertex often continues to work (those clouds have their own Claude infrastructure with separate failure domains). Enabling auto mode on Bedrock or Vertex gives you a fallback path that does not depend on Anthropic's first-party servers being healthy.
File-write protection for shell startup and build configs
Claude Code now prompts before writing files that can execute code at startup or build time, even when acceptEdits mode is active. The protected file set:
- Shell startup: .zshenv, .bash_login, .bash_profile, .profile, .zlogin
- Git config: ~/.config/git/, .gitconfig
- Build tool configs: .npmrc, .bazelrc, .pre-commit-config.yaml
This is a security hardening response to the prompt injection risk surface that has been growing as Claude Code agents become more autonomous. Without this protection, a sufficiently crafty prompt injection could cause Claude Code to write a malicious entry to .zshenv that runs the next time the user opens a shell, effectively persisting attacker code outside the Claude Code session.
The protection is good. The list of files is well-chosen. If you have a workflow that writes to these files as part of normal development, you will see one extra prompt; you can override case by case.
/plugin list and managed deployment version controls
The new /plugin list command shows every plugin loaded in the current session with its version. This is mundane but useful: previously you had to dig through your settings to know what was active.
Managed deployment version controls allow enterprise admins to pin specific Claude Code versions across their organization and roll updates out gradually. Relevant if you are deploying Claude Code to a team of 50+ developers.
Mid-stream connection drop fix
This one matters during the outage period. Previously, if your API connection dropped mid-stream while Claude was generating a response, the partial response was discarded. The June 17 release adds resilient reconnection logic that preserves the partial response and continues generation. For users hitting intermittent connection drops (which is exactly what happens during Anthropic infrastructure incidents), this is a meaningful UX improvement.
Other fixes in the release: scrolling and focus bugs in fullscreen mode, remote session task state synchronization, plugin loading performance, survey and welcome banner polish, subagent viewing improvements.
What builders should actually do this week
The outages are not going to stop overnight. Anthropic is scaling, but scaling takes weeks of capacity work, not days. Here is the practical playbook for builders, ranked by impact.
1. Enable auto mode on Bedrock or Vertex as a fallback
If you are running Claude Code primarily through Anthropic's first-party API, configure Bedrock or Vertex as a fallback. The June 17 release means you can now run auto mode there with feature parity to the first-party experience. When Anthropic's first-party API has an incident (and they will continue to), your fallback path keeps working.
This is a 30-minute setup if you already have an AWS or GCP account. Even if you do not use it daily, having it tested and ready means you can flip a switch during the next incident instead of scrambling to set it up under pressure.
2. Implement client-side retry with exponential backoff
Many of the recent incidents involve transient errors that resolve themselves on retry. If your application calls the Claude API directly, implement retry logic with exponential backoff (start at 1 second, double on each failure, cap at 60 seconds). This is standard distributed systems practice and would mask most of the recent incidents from your end users.
The official Anthropic SDK supports retry configuration. The simplest pattern in Python:
from anthropic import Anthropic
client = Anthropic(max_retries=5)
In Node:
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic({ maxRetries: 5 });
3. Subscribe to status.claude.com for real-time incident alerts
The Anthropic status page supports email and webhook subscriptions. Set up a Slack or email alert so your team knows about an incident before your users tell you. Most of the recent incidents were posted to the status page within minutes of detection, but if you are not subscribed, you have to refresh manually.
For teams that build mission-critical Claude integrations, consider also subscribing to status pages for Bedrock and Vertex AI so you know if your fallback path is healthy.
4. Cache aggressively (Anthropic's prompt caching is your friend)
The more cache hits you get, the fewer requests you make to the underlying API, and the more resilient you are to backend strain. Anthropic's prompt caching has been generally available for over a year now and is well-documented. If you have not implemented it in your Claude application, this week is the week. Caching also has cost benefits (cache reads are 0.10x the cost of fresh inputs), so it is a win even without the reliability angle.
5. Have a multi-provider fallback for the highest-stakes paths
This is the harder one. If you have a Claude integration where downtime equals revenue loss (customer-facing chatbot, agent-driven sales tool, real-time content generation), you probably want a second provider for the absolute worst case. OpenAI's GPT-5.5 and Google's Gemini 3 Pro are the practical alternatives.
The trade-off is real: maintaining two prompt sets and two API integrations is more work, and the quality is rarely identical. But for stakes high enough, the cost is worth it. The pattern I have seen work: run all production traffic through Claude, route to GPT-5.5 only when Claude has been failing for more than 60 seconds, and log every fallback event so you can review.
6. Adjust your Claude Code workflows for the file-write protection
If your Claude Code agents previously wrote to .zshenv, .bash_login, or any of the protected files as part of normal flow, you will now see permission prompts. Two options:
One: confirm each prompt manually. Acceptable if it happens once or twice per session.
Two: adjust your skill or workflow to write to a non-protected file and source it from the protected file once, manually. This keeps the security benefit while removing the friction.
This matters if you have automation that depends on Claude Code running without human intervention (CI workflows, scheduled jobs).
The bigger picture
The outage streak is a story about an AI company learning to scale infrastructure in real time. It is also a story about the dual pressure of growing demand and a high-profile public dispute (the Pentagon case) that is bringing in new developers faster than the company can build capacity.
For builders, the practical answer is the same as it has been for any reliability story: redundancy, retries, monitoring, fallbacks. The tools to do this are all available; Anthropic is actively shipping features that make redundancy easier (auto mode on Bedrock and Vertex being the most significant in the June 17 release).
The critique that Anthropic is shipping features while reliability is suffering is partly fair and partly wrong. Reliability fixes (the mid-stream reconnection logic, for example, and the file-write protection) shipped in the same release as the new features. Stopping feature work to firefight reliability is rarely the right move at the company stage; you ship the reliability fixes alongside, and you increase capacity in parallel.
The most honest read of the current moment: Anthropic is in a high-growth phase that is straining their infrastructure, they are publicly acknowledging it on the status page and elsewhere, they are shipping fixes weekly, and they are giving builders new tools (auto mode on Bedrock/Vertex/Foundry) to route around the strain. If you build on Claude, the answer is not to leave; it is to engineer for the current reality.
What to watch for in the next two weeks
A few things to monitor:
Capacity expansion announcements. Anthropic has not yet announced a specific capacity addition tied to the recent outages. If they do (a new region, a new compute partner, a new tier of API limits), the timeline of recovery becomes clearer. Watch the official news page at anthropic.com/news.
Whether the outage cadence accelerates or slows. If we go a full week without a significant incident, capacity has caught up. If we see another 5 outages in the next 7 days, the underlying gap is bigger than what is being publicly acknowledged.
Whether Bedrock and Vertex outages start to mirror first-party Anthropic outages. They have separate failure domains today, but if the root cause is shared infrastructure (the model-serving substrate), they could correlate. Monitor your fallback path independently.
Any further developments in the Pentagon case. The case is in appeals court and the outcome will affect Anthropic's enterprise positioning. A win for Anthropic likely accelerates further enterprise adoption (and therefore further strain). A loss likely shifts the demand picture.
Related reading on clskillshub.com
- The 7 Patterns Behind High-Performance Claude Prompts — the prompt patterns that maximize cache hit rates, which matter even more during periods of infrastructure strain
- Anthropic's June 15 Agent SDK Credit Change — the billing split that rolled out on June 15 and is part of the broader infrastructure story
- Claude Code This Week (May 8-15, 2026) — the Agent View release that landed last month
- Pricing page — the full clskillshub catalog of skills, packs, and tools
Sources
- Claude Status page
- Claude Status incident history
- Claude Code release notes (Releasebot)
- Anthropic news
- Anthropic-DOD dispute (Wikipedia)
- Claude Outage: Tenth Disruption in 12 Days (TechTimes)
- Anthropic acknowledges Opus 4.6 disruption (Storyboard18)
- Pentagon reduces reliance on Anthropic (Crypto Briefing)
Reply on the newsletter if you want help auditing your Claude integration for the kind of failures the recent incidents have surfaced, or if you have observations from your own usage that contradict what I have written here. I read every reply.